This section assumes you have finished Tutorials Part 1 and Part 2
Unfiltered taxon counts
The taxonLevelCounts.tsv file is intended to make it quick and easy to compare virus hit counts across samples.
Let's take a look at it:
View(taxonCounts)
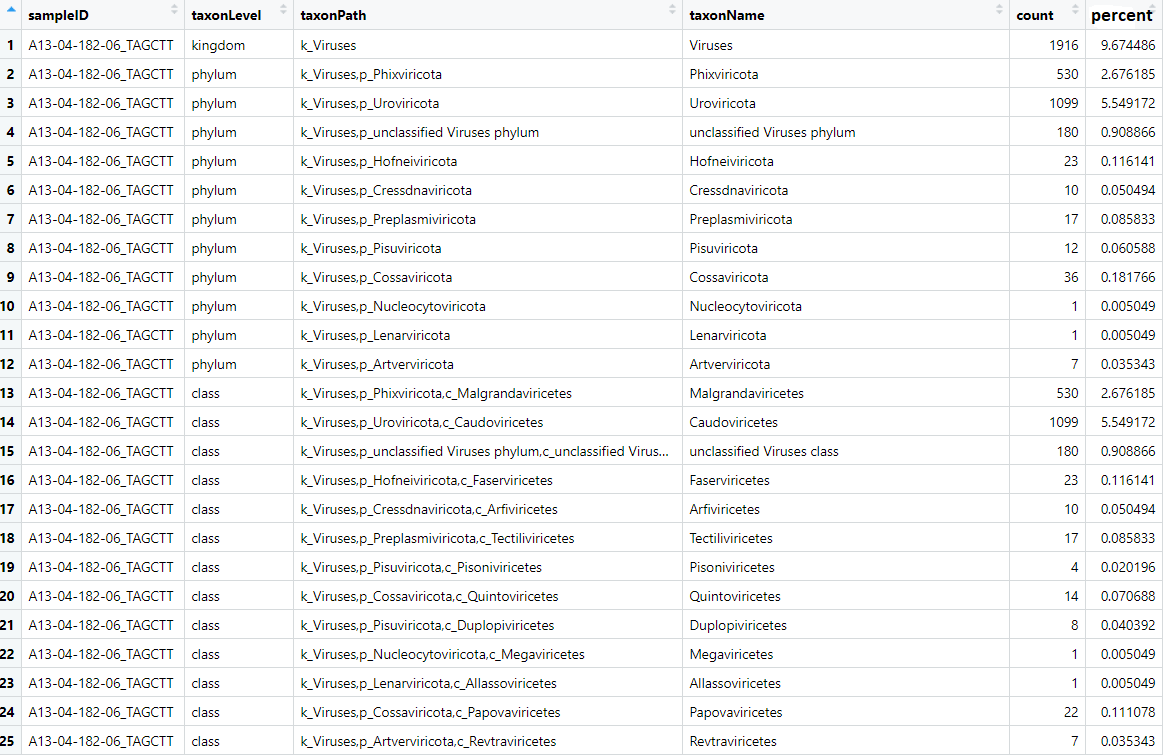
The file contains the counts and normalised counts for each taxonomic level, for each sample, based on the raw (unfiltered) hit counts. If we wanted to compare the number of Adenoviridae hits between each sample we could pull out the Adenoviridae counts and plot them:
# get adenoviridae counts
adenoCounts = taxonCounts %>%
filter(taxonLevel=='family',taxonName=='Adenoviridae')
# plot
ggplot(adenoCounts) +
geom_bar(aes(x=sampleID,y=count),stat='identity') +
coord_flip()
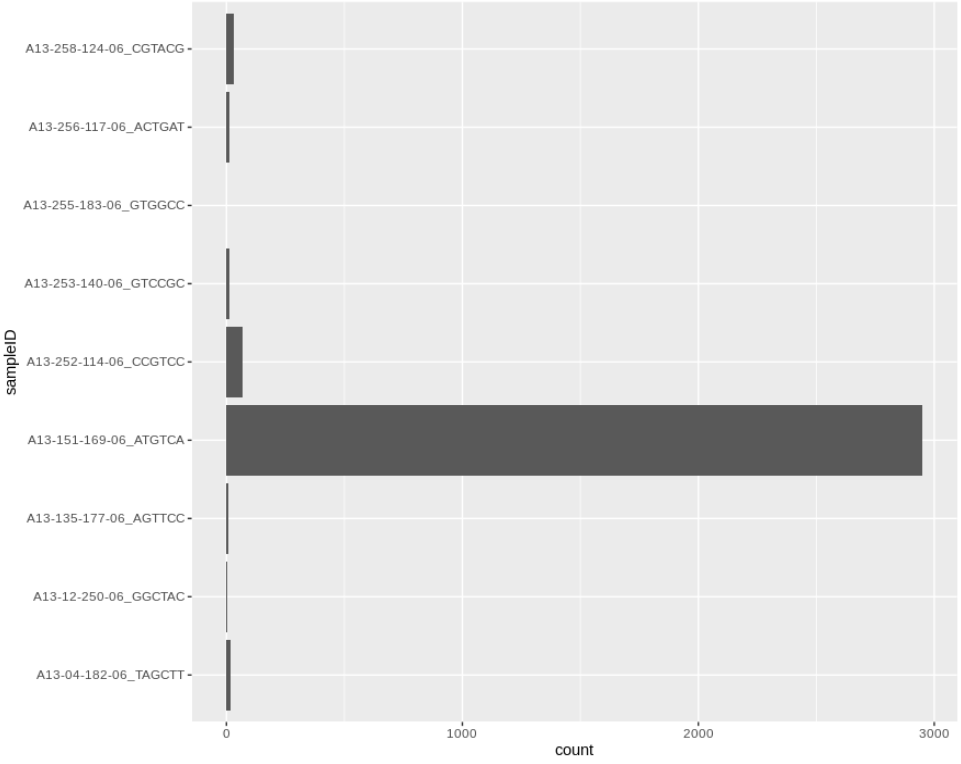
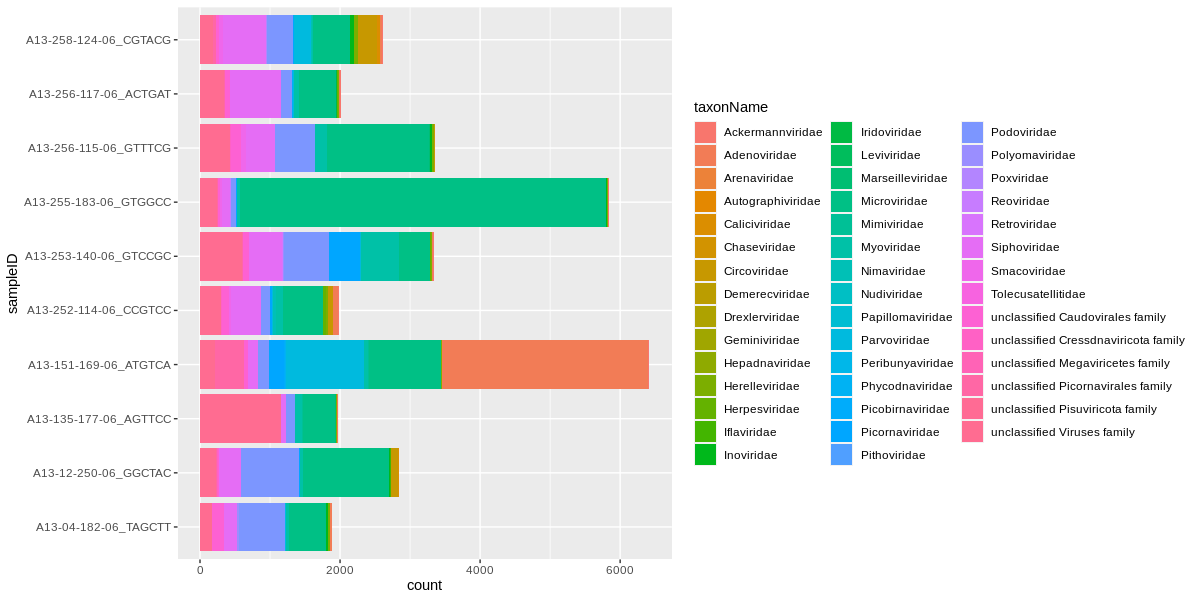
We can take this one step further and plot all the viral family normalised counts for each sample, in a stacked bar chart:
# get all viral family counts
viralCounts = taxonCounts %>%
filter(taxonLevel=='family',grepl('k_Viruses',taxonPath))
# plot
ggplot(viralCounts) +
geom_bar(aes(x=sampleID,y=count,fill=taxonName),position='stack',stat='identity') +
coord_flip()
Generating taxon counts
The taxonLevelCounts.tsv file is convenient for comparing the raw counts,
but you will likely want to generate new counts from your filtered hits.
Recreate the above plot from the filtered hits by first summing the counts
or normalised counts (i.e. the percent of reads), for instance at the family level:
# Answer for "Challenge: Filter your raw viral hits to only keep protein hits with an evalue < 1e-10"
virusesFiltered = viruses %>%
filter(alnType=='aa',evalue<1e-10)
# collect the filtered counts
viralFiltCounts = virusesFiltered %>%
group_by(sampleID,family) %>%
summarise(n = sum(percent))
Then plot again.
This time we use position='fill' to make it look like 16s data, so we can confuse people.
We'll also add theme_bw() because grey is ugly:
ggplot(viralFiltCounts) +
geom_bar(aes(x=sampleID,y=n,fill=family),position='fill',stat='identity') +
coord_flip() +
theme_bw()
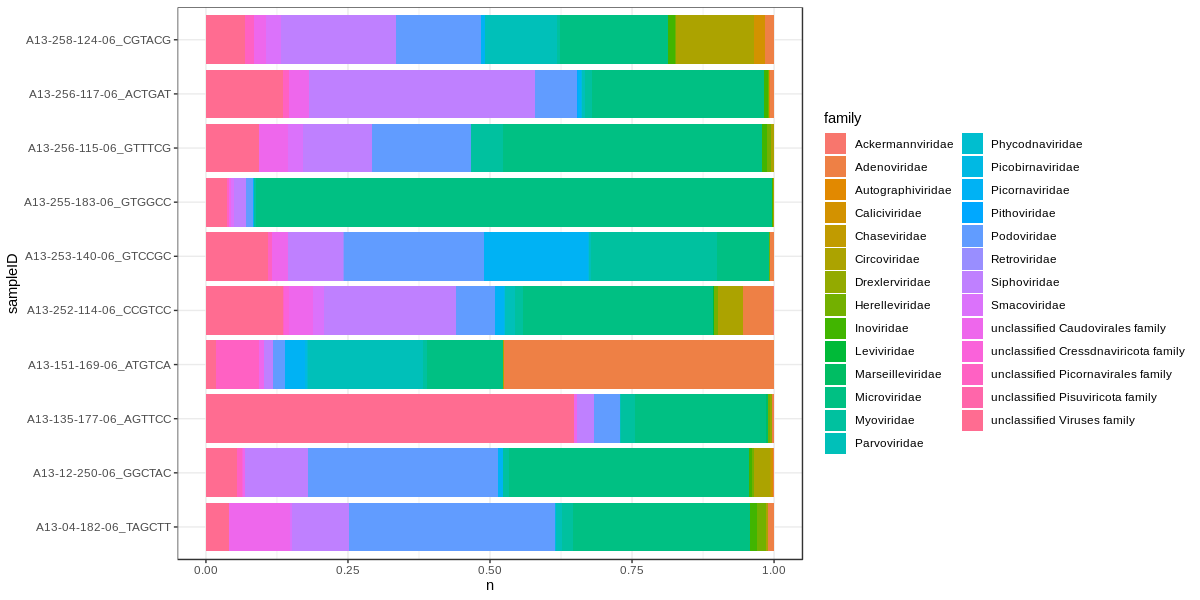
These count tables we will use for plotting and some statistical comparisons.
Challenge
Make a stacked bar chart of the viral families for the Male and Female monkeys
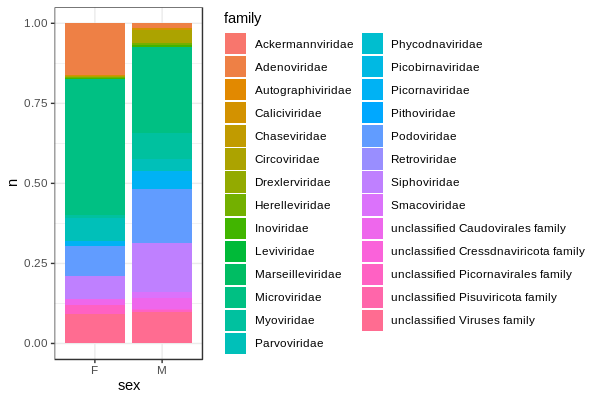
Visualising groups
We have a few viral families that are very prominent in our samples.
For the purposes of the tutorial we have a completely made up sample group category called sampleGroup,
but pretend we're looking at case and control samples for a disease or something.
Let's see if there is a difference in viral loads according to our sample groups.
Collect sample counts for Microviridae.
Include the metadata group in group_by() so you can use it in the plot.
microCounts = virusesFiltered %>%
group_by(family,sampleID,sampleGroup) %>%
filter(family=='Microviridae') %>%
summarise(n = sum(percent))
And plot. I like jitter plots but boxplots or violin plots might work better if you have hundreds of samples.
ggplot(microCounts) +
geom_jitter(aes(x=sampleGroup,y=n),width = 0.1) +
theme_bw()
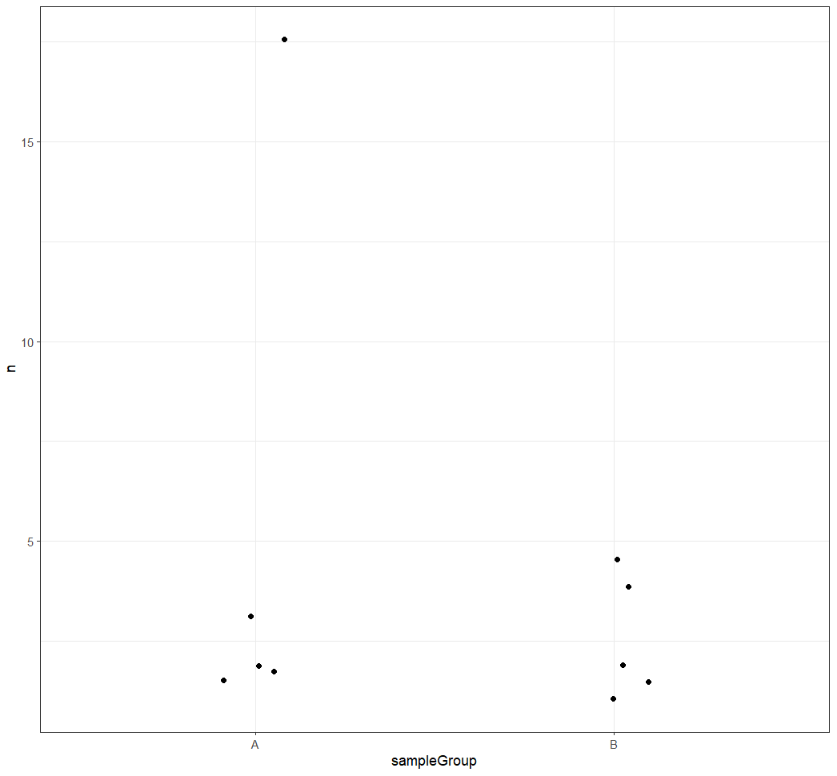
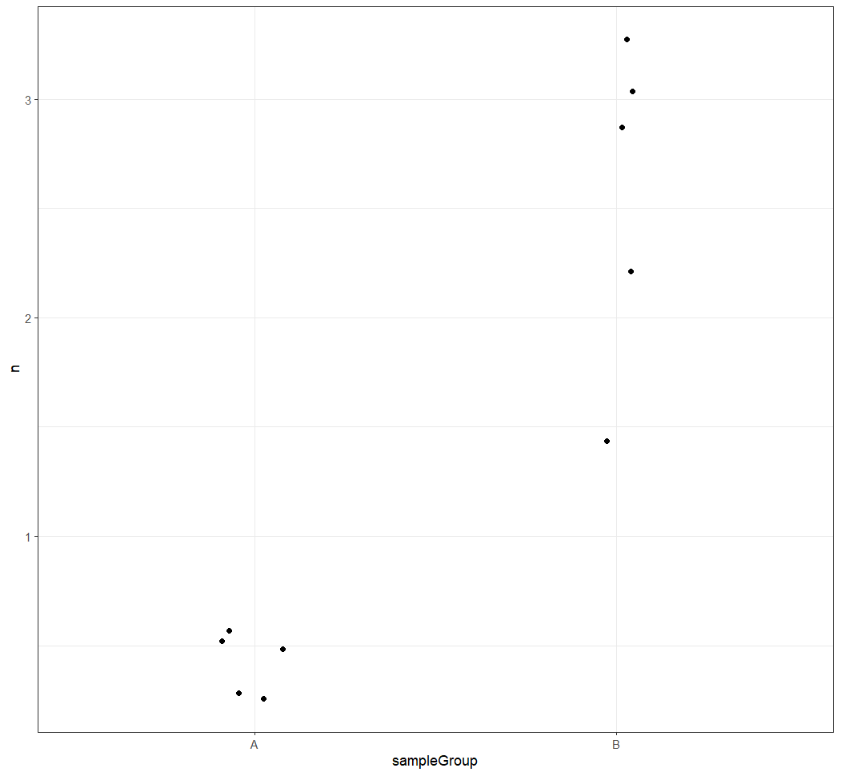
Let's do the same for Podoviridae.
# collect counts
podoCounts = virusesFiltered %>%
group_by(family,sampleID,sampleGroup) %>%
filter(family=='Podoviridae') %>%
summarise(n = sum(percent))
# plot
ggplot(podoCounts) +
geom_jitter(aes(x=sampleGroup,y=n),width = 0.1) +
theme_bw()
Challenge
Could gender be a good predictor of viral load for these families?
While the sampleGroup looks promising for Podoviridae, we'll need to move on to Part 4: statistical tests to find out for sure.